One of the most popular tools in the shed of machine learning researchers today is deep neural architectures. Deep nets enable agents to solve seemingly arbitrarily complex problems, from autonomously creating images of never-seen faces, to defeating the world champion of the game of Go. The pitfall of these methods is the amount of data they require: millions or even billions of data points may need to be provided to the agent in order to learn robust predictors. And then, what happens if the agent is required to learn a new task? Typical deep learning methods would start from scratch, discarding any useful information they may have discovered on previous tasks.
Our research group is creating deep neural network architectures and algorithms that explicitly deal with the problem of knowledge accumulation throughout a sequence of related tasks. These methods enable the agent to reuse knowledge from previously seen tasks to reduce the amount of data required to solve future tasks. Moreover, they avoid forgetting how to solve the earlier tasks.
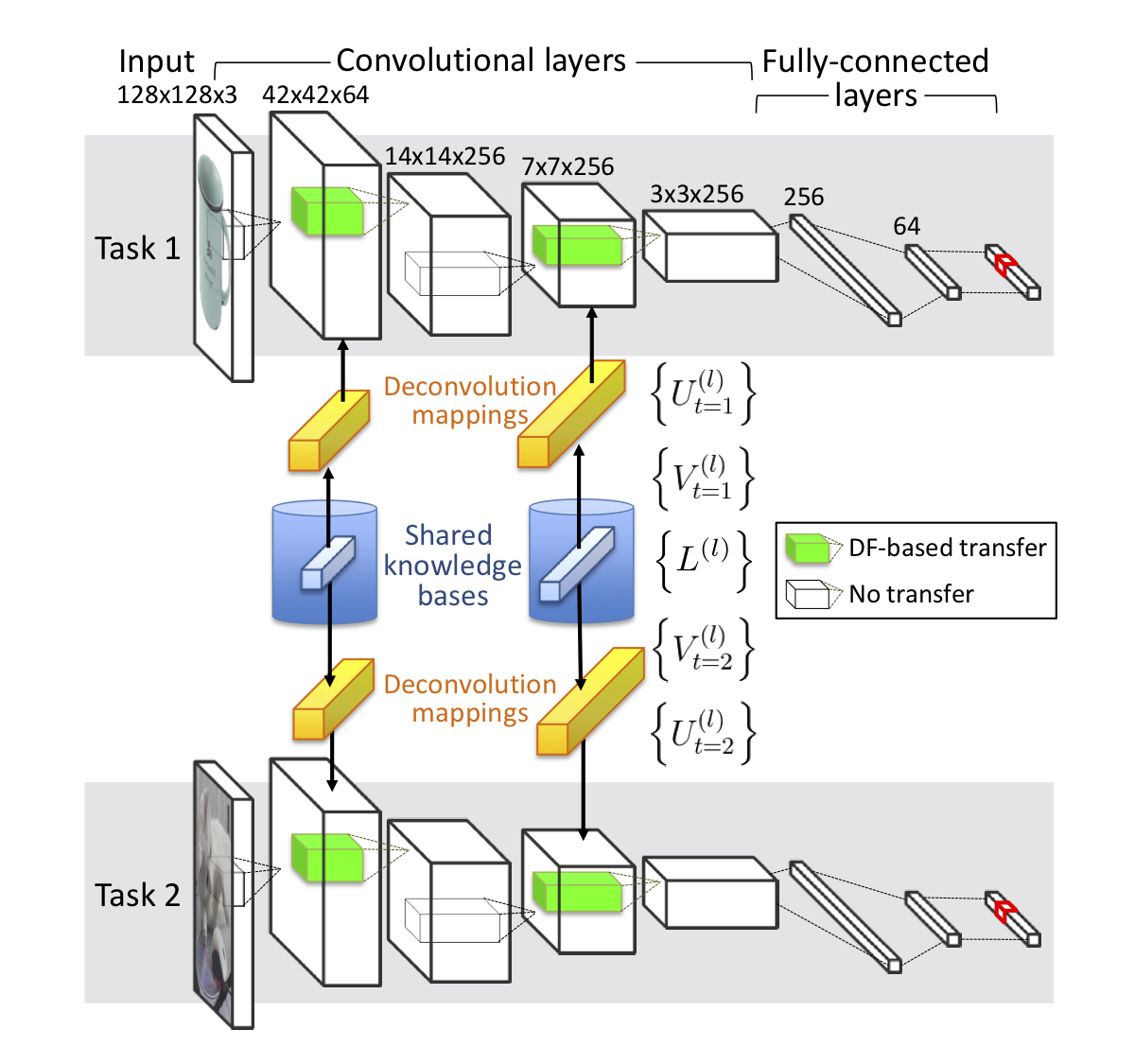
Under this project, our group developed the deconvolutional factorized CNN [IJCAI 2019]. Instead of using the same convolutional filters for multiple tasks, the convolutional filters are dynamically generated from a task-independent layer-dependent shared tensor through a task-specific deconvolutional operation and tensor contraction. This transfer architecture enables the DF-CNN to learn and compress knowledge universal among the observed tasks into the shared tensors, and adapt this knowledge to each individual task through the deconvolution and contraction operations.
Lifelong Compositional Learning
While most work on lifelong machine learning focuses on avoiding catastrophic forgetting, a true lifelong learner should achieve much more than that: it should be able to accumulate knowledge over time and learn to reuse it to quickly solve new problems. In particular, if this accumulated knowledge is represented in compositional structures, then chunks of this knowledge could be combined in different ways, dramatically increasing their reusability.
Our group is developing some of the first algorithms for lifelong learning of compositional structures. These methods will enable learners to autonomously discover self-contained, reusable, and interpretable pieces of knowledge. The learner can then not only reuse these existing components for future tasks, but also adapt them over time to deal with both changes in the environment and the agent’s own evolving ability to perceive the environment.
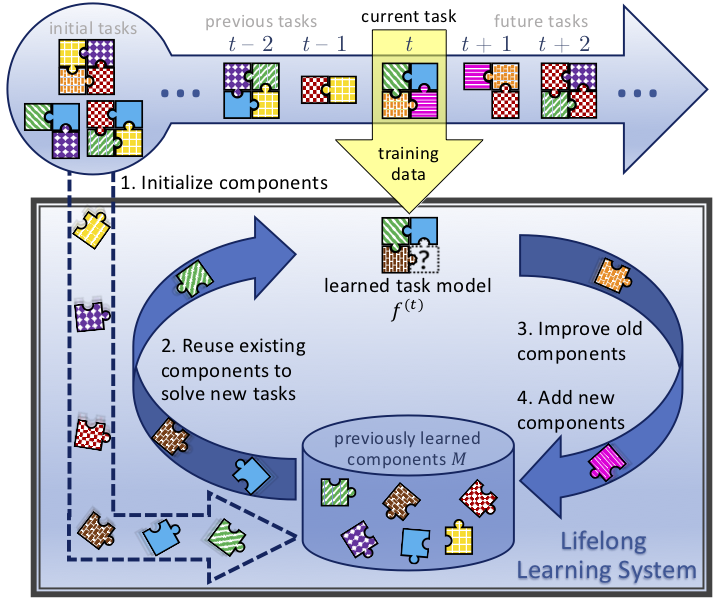
As part of this project, our group developed a general-purpose framework for lifelong compositional learning [ICLR 2021]. The framework is split into four broad steps: 1) initialize components on the first few tasks encountered by the agent to encourage reusability; upon encountering each new task, 2) attempt to solve the problem by combining the existing components without modifying them; once the correct components have been selected, incorporate new knowledge into the components by either 3) adapting the components or 4) creating fresh components. This framework can incorporate a variety of forms of compositional structures and base lifelong learning methods, and empirically demonstrates far superior performance as compared to existing monolithic lifelong approaches.
Lifelong Reinforcement Learning
Reinforcement learning (RL) endows artificial agents with the ability to learn to act in the world autonomously by interacting with the environment and processing feedback from the environment. This has the potential to create sophisticated systems that are capable of intelligently interacting with the world around them to maximize their utility. A prime example of this kind of behavior has been AlphaGo, the first computer to defeat a Go world champion. However, the downside of typical RL methods is that they tend to be specialized to very concrete tasks. Instead, we want our agents to be able to act more generally, solving a diversity of tasks, and becoming better learners over time.
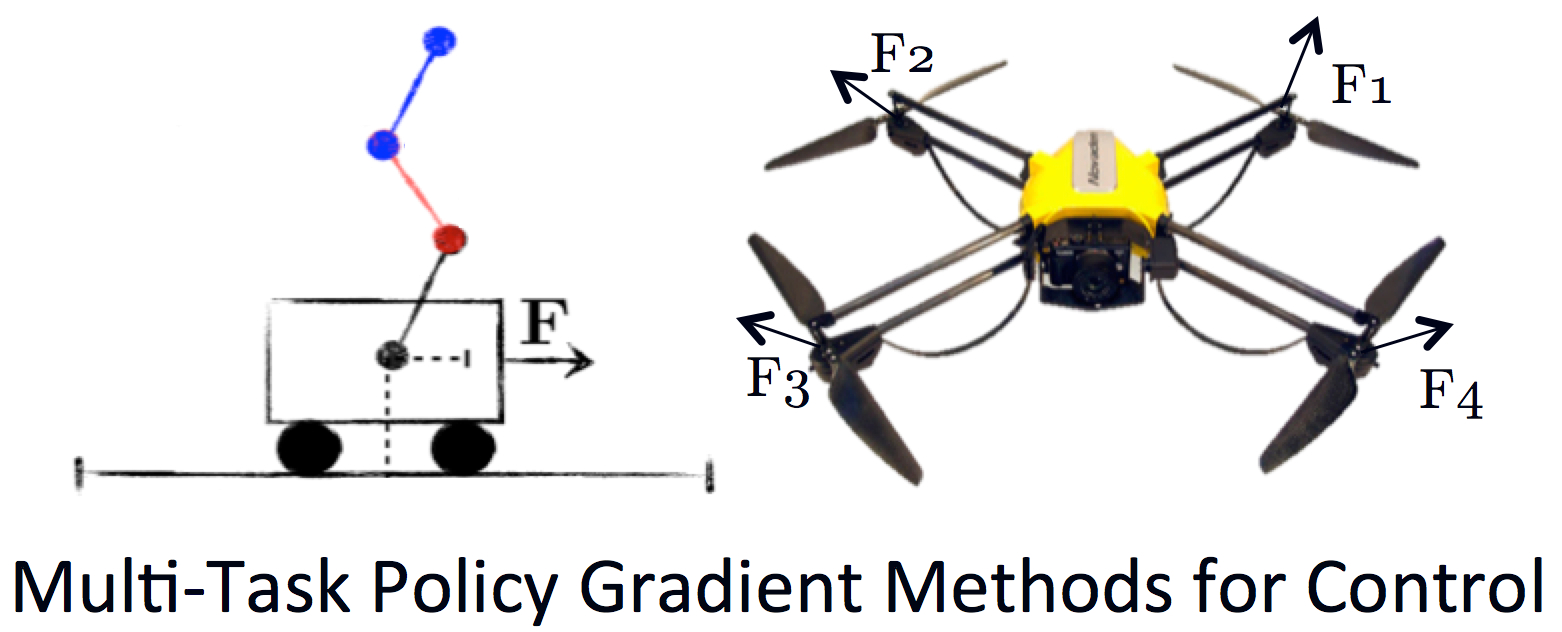
Our group has developed lifelong RL methods, in particular using policy gradient algorithms. Our PG-ELLA algorithm [ICML 2014] uses a shared basis to transfer knowledge between multiple sequential decision making tasks, and provides a computationally efficient method of learning new control policies by building upon previously learned knowledge. Rapid learning of control policies for new systems is essential to minimize both training time as well as wear-and-tear on the robot. We applied PG-ELLA to learn control policies for a variety of dynamical systems with non-linear and highly chaotic behavior, including an application to quadrotor control. We also developed a fully online variant of this approach with sublinear regret that incorporates safety constraints [ICML 2015], and applied this technique to disturbance compensation in robotics [IROS 2016].
Our most recent extension of this work, lifelong policy gradients: faster training without forgetting (LPG-FTW) [NeurIPS 2020], extends the ideas of PG-ELLA to more complex settings. This has enabled applying LPG-FTW to diverse robotic manipulation tasks using deep neural network policies. LPG-FTW was much faster at learning new tasks than learning them from scratch, and was the only lifelong method capable of handling a set of 48 highly varied manipulation tasks.
Autonomous Mobile Service Robots
Our research group is developing a fleet of highly-capable autonomous service robots that can operate continually in university, office, and home environments. We previously developed a low-cost version 1 platform, shown left giving a tour to prospective PhD students. We are currently developing a new platform, shown right, which is designed to learn a wide variety of skills involving perception, navigation, control, and multi-robot coordination over safe autonomous long-term deployments, serving as a major testbed for lifelong machine learning algorithms.
In one of the very many use-cases, visitors to the GRASP lab can be greeted and taken on a small tour by the robots around some of the engineering laboratories at Penn. The left video below shows the fully-developed version 1 service robot giving a 7-minute tour across the halls. The video on the right shows the version 2 service robot acting as a lifelong learning testbed in a realistic scenario, by completing an autonomous scavenger hunt evaluated with browser-based verification using UT Austin’s Scavenger Hunt API.
Previous Projects
Lifelong Learning using Factorized Representations
Lifelong learning is essential for an intelligent agent that will persist in the real world with any amount of versatility. Animals learn to solve increasingly complex tasks by continually building upon and refining their knowledge. Virtually every aspect of higher-level learning and memory involves this process of continual learning and transfer. In contrast, most current machine learning methods take a “single-shot” approach in which knowledge is not retained between learning problems.
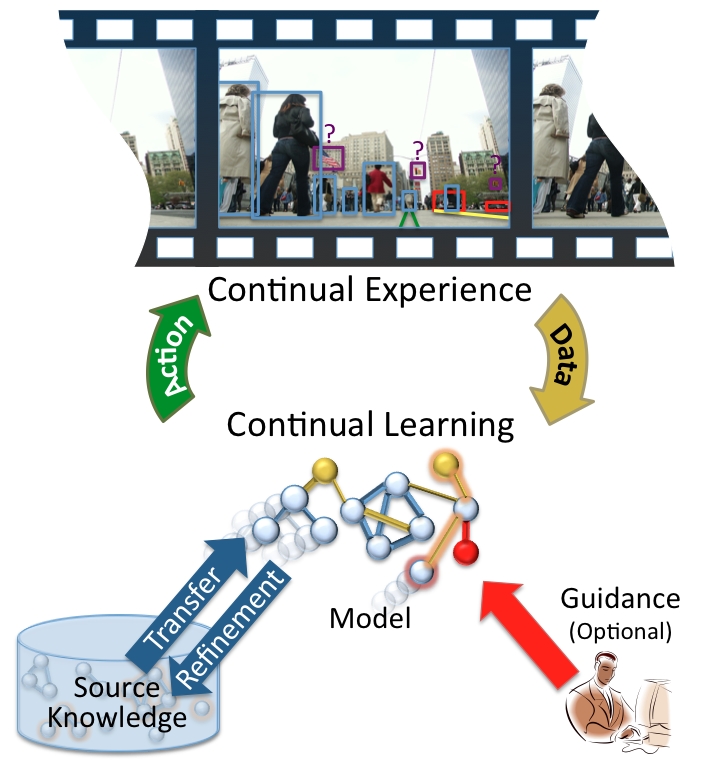
My research seeks to develop lifelong machine learning for intelligent agents situated for extended periods in an environment and faced with multiple tasks. The agent will continually learn to solve multiple (possibly interleaved) tasks through a combination of knowledge transfer from previously learned models, revision of stored source knowledge from new experience, and optional guidance from external teachers or human experts. The goal of this work is to enable persistent agents to develop increasingly complex abilities over time by continually and synergistically building upon their knowledge. Lifelong learning could substantially improve the versatility of learning systems by enabling them to quickly learn a broad range of complex tasks and adapt to changing circumstances.
ELLA: Lifelong Learning for Classification and Regression
Under this project, we developed the Efficient Lifelong Learning Algorithm (ELLA) [ICML 2013] – a method for online multi-task learning of consecutive tasks that has equivalent performance to batch multi-task learning with over a 1,000x speedup. ELLA learns and maintains a repository of shared knowledge, rapidly learning new task models by building upon previous knowledge. ELLA provides a variety of theoretical guarantees on performance and convergence, along with state-of-the-art performance on supervised multi-task learning problems. It also supports active task selection to intelligently choose the next task to learn in order to maximize performance [AAAI 2013].
Lifelong Reinforcement Learning for Robotic Control
We extended the ELLA framework to reinforcement learning settings, focusing on policy gradient methods [ICML 2014]. Policy gradient methods support sequential decision making with continuous state and action spaces, and have been use with great success for robotic control. Our PG-ELLA algorithm incorporates ELLA’s notion of using a shared basis to transfer knowledge between multiple sequential decision making tasks, and provides a computationally efficient method of learning new control policies by building upon previously learned knowledge. Rapid learning of control policies for new systems is essential to minimize both training time as well as wear-and-tear on the robot. We applied PG-ELLA to learn control policies for a variety of dynamical systems with non-linear and highly chaotic behavior, including an application to quadrotor control. We also developed a fully online variant of this approach with sublinear regret that incorporates safety constraints [ICML 2015], and applied this technique to disturbance compensation in robotics [IROS 2016].
Autonomous Cross-Domain Transfer
Despite their success, these approaches only support transfer between RL problems with the same state-action space. To support lifelong learning over tasks from different domains, we developed an approach for autonomous cross-domain transfer in lifelong learning [IJCAI 2015 Best Paper Nomination]. For the first time, this approach allows transfer between radically different task domains, such as from cart pole balancing to quadrotor control.
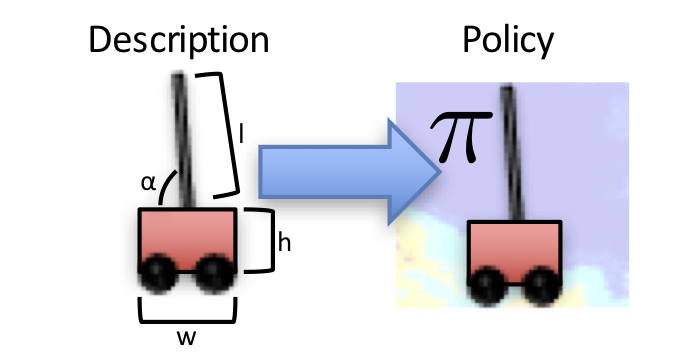
Zero-Shot Transfer in Lifelong Learning using High-Level Descriptors
To further accelerate lifelong learning, we showed that providing the agent with a high level description of each task can both improve transfer performance and support zero-shot transfer [IJCAI 2016 Best Student Paper]. Given only a high level description of a new task, this approach can predict a high performance controller for the new task immediately through zero-shot transfer, allowing the agent to immediately perform on the new task without expending time to gather data before it can perform.
Interactive Artificial Intelligence
My research on interactive AI methods seeks to give users extensive control over reasoning and learning processes. In many critical applications, especially in military and medical domains, users will reject traditional AI automation without the ability for each result to be checked and altered by a human operator. Interactive AI methods incorporate such levels of user control to facilitate the transition of AI into these types of applications. This interactive AI paradigm combines user-driven control with the complementary system-driven approach of active learning.
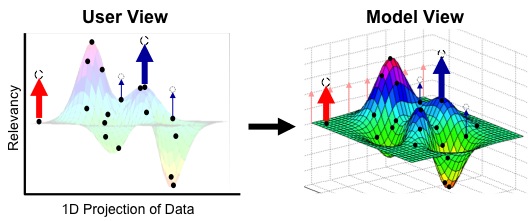
A Manifold-Based Approach to Interactive Learning
At Lockheed Martin, I led the development of an interactive AI method based on manifold learning (left figure) that trains a regression function in collaboration with the user [Eaton, Holness, & McFarlane in AAAI 2010]. This approach was applied to a naval system used to ensure the safety of shipping ports—a critical application in which watchstanders require the ability to rapidly adjust the model in response to changing mission requirements. This method generalizes user feedback on individual vessels to alter the model in an intuitive manner that monotonically improves performance with any correction, providing the first such guarantee of any interactive learning method. This technique could also be applied to other systems used by network security analysts, stock traders, and crisis monitoring centers.
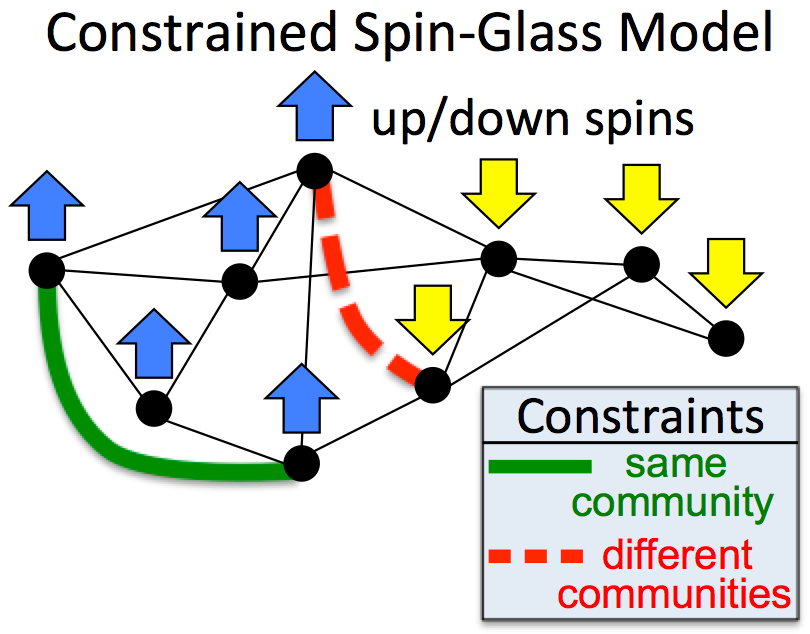
Semi-Supervised Community Detection
My group also developed an interactive method (right figure) for incorporating user guidance and background knowledge into the community detection process using a semi-supervised spin-glass model [Eaton & Mansbach, AAAI 2012]. We focused on scenarios in which there was noise in the relational network, and showed that popular modularity-based community detection algorithms perform poorly as the network becomes increasingly noise. We showed that semi-supervision could be integrated into a spin-glass model for community detection, providing robust performance in noisy networks. We also showed that this semi-supervised spin-glass model yields an alternate form of Newman-Girvan graph modularity that incorporates background information, enabling existing modularity-based community detection algorithms to be easily modified to incorporate semi-supervision.
Selective Knowledge Transfer
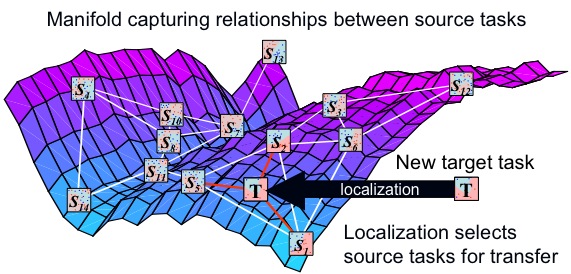
My dissertation research [Eaton, 2009] focused on the problem of source selection in transfer learning: given a set of previously learned source tasks, how can we select the knowledge to transfer in order to best improve learning on a new target task? In this context, a task is a single learning problem, such as learning to recognize a particular visual object. Until my dissertation, the problem of source knowledge selection for transfer learning had received little attention, despite its importance to the development of robust transfer learning algorithms. Previous methods assumed that all source tasks were relevant, including those that provided irrelevant knowledge, which can interfere with learning through the phenomenon of negative transfer.
My results showed that proper source selection can produce large improvements in transfer performance and decrease the risk of negative transfer by identifying the knowledge that would best improve learning of the new task. This aspect can be measured by the transferability between tasks – a measure, introduced in my dissertation, of the change in performance between learning with and without transfer.
I developed selective transfer methods based on this notion of transferability for two general scenarios: the transfer of individual training instances [Eaton & desJardins, 2011; Eaton & desJardins, 2009] and the transfer of model components between tasks [Eaton, desJardins & Lane in ECML 2008]. In particular, my research on model-based transfer showed that modeling the transferability relationships between tasks using a manifold provides an effective framework for source knowledge selection, providing a geometric framework for understanding how knowledge is best transferred between learning tasks.
Constrained Clustering
Constrained clustering uses background knowledge in the form of must-link constraints, which specify that two instances belong in the same cluster, and cannot-link constraints, which specify that two instances belong in different clusters, to improve the resulting clustering. My Master’s thesis work [Eaton, 2005] focused on a method for propagating a given set of constraints to other data instances based on the cluster geometry, decreasing the number of constraints needed to achieve high performance. This method for constraint propagation was later used as the foundation for the first mult-view constrained clustering method that supports an incomplete mapping between views [Eaton, desJardins, & Jacob in KAIS 2012; Eaton, desJardins, & Jacob in CIKM 2010]. In this method, clustering progress in one view of the data (e.g., images) is propagated via a set of pairwise constraints to improve learning performance in another view (e.g., associated text documents). The key contribution of this work is that it supports an incomplete mapping between views, enabling the method to be successfully applied to a larger range of applications and legacy data sets that have multiple views available for only a limited portion of the data.
Learning User Preferences over Sets of Objects
In collaboration with Marie desJardins (UMBC) and Kiri Wagstaff (NASA Jet Propulsion Laboratory), I developed the DDPref framework for learning and reasoning about a user’s preferences for selecting sets of objects where items in the set interact [desJardins, Eaton & Wagstaff, 2006; Wagstaff, desJardins & Eaton, 2010]. The DDPref representation captures interactions between items within a set, modeling the user’s desired levels of quality and diversity of items in the set. Our approach allows a user to either manually specify a preference representation, or select example sets that represent their desired information, from which we can learn a representation of their preferences. We applied the DDPref method to identify sets of images taken by a remote Mars rover for transmission back to the user. Due to the limited communications bandwidth, it is important to send back a set of images which together captures the user’s desired information. This research is also applicable to search result set creation, automatic content presentation, and targeted information acquisition.